The Open vs. Closed Model Decision in 2026: A Framework That Actually Works


The open-weight vs. closed-API model decision has gotten more nuanced and more contentious over the past 18 months. There are strong opinions on both sides that are often driven by ideology rather than analysis. Here's the framework I actually use with clients, which is grounded in what matters operationally.
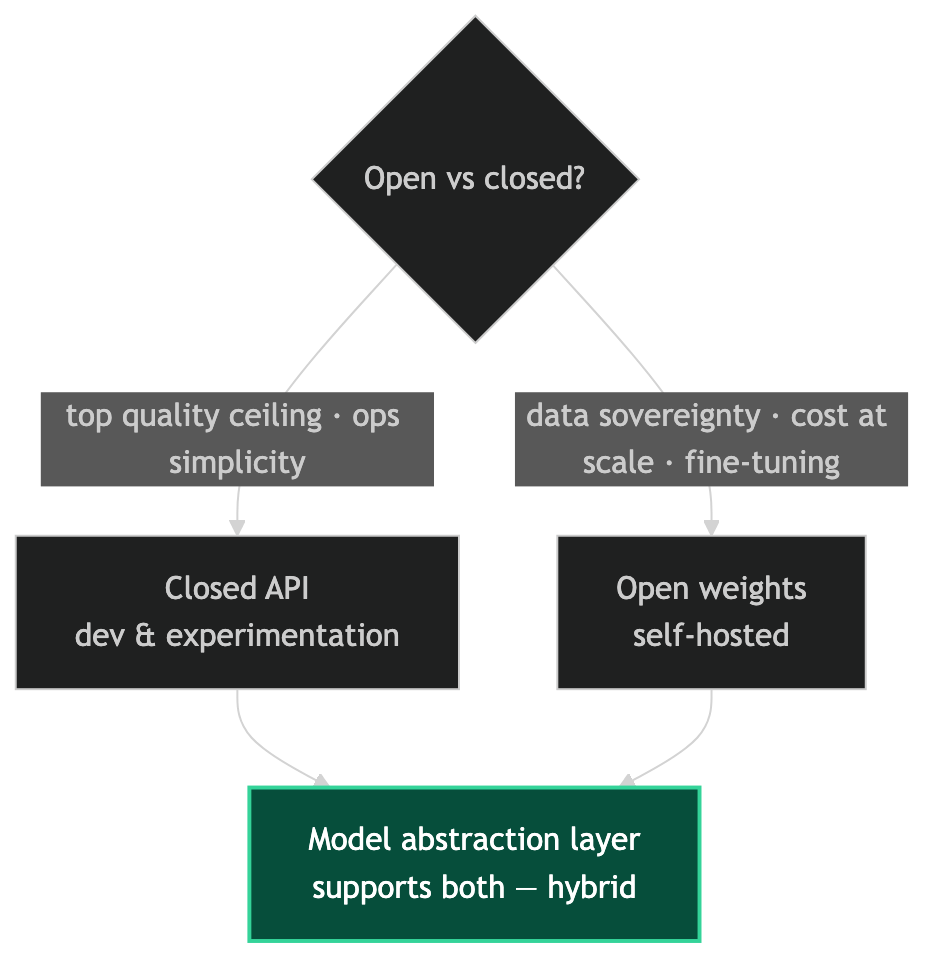
Factors That Favor Closed APIs
Task quality ceiling: for tasks where the absolute best output quality matters — complex reasoning, nuanced prose, multi-step code generation — closed frontier models still have an edge for some tasks. If you're optimizing for quality and cost is secondary, start with the best closed model.
Operational simplicity: a closed API is an HTTP call. No GPU infrastructure, no model serving layer, no CUDA compatibility issues. For small teams without dedicated MLOps capability, the operational simplicity of a closed API is worth a significant cost premium.
Factors That Favor Open Weights
Data sovereignty: if your data cannot leave your network perimeter, you have no choice but to run on-premises or in your own cloud environment. Open weights are the only option.
Cost at scale: at high enough request volumes, the per-token premium of closed APIs exceeds the infrastructure cost of self-hosted inference. The crossover point depends on your volume and hardware costs, but it's real and calculable.
Fine-tuning on domain data: you can fine-tune open weights on your data. You cannot fine-tune a closed model on data that doesn't leave your environment.
The Hybrid Is Usually the Answer
Most production environments I work with use closed APIs for development and experimentation, and migrate high-volume stable workloads to open-weight self-hosted when the economics justify it. The architecture should support both through a model abstraction layer. Don't paint yourself into one corner. I'm here to help design the right split for your workload profile.