Prompt Hygiene at Scale


Prompt hygiene is not a glamorous topic. It doesn't make a good conference talk. It doesn't generate engagement on social media. It is, however, the difference between an AI-assisted workflow that you can trust with real work and one that will eventually cause you a problem you can't fully explain to a client.
Two and a half years of building AI workflows into professional consulting work has produced specific, hard-won rules about what goes into prompts and what doesn't. Here they are.
Rule 1: No Secrets in Prompts. Ever.
API keys, database credentials, client account identifiers, personal information, and anything that belongs in a secrets manager do not belong in prompts. This sounds obvious. It's violated constantly.
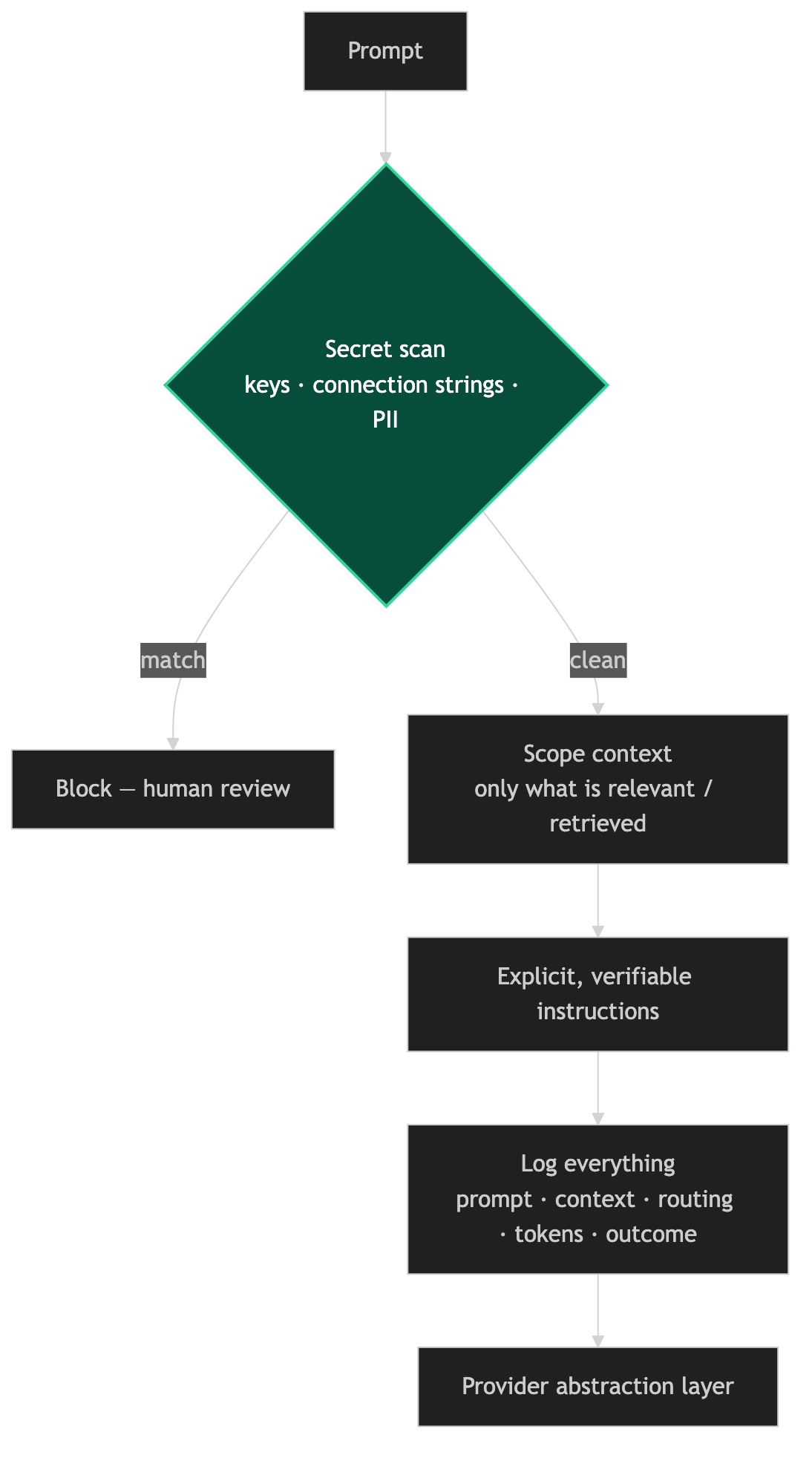
The violation usually happens because someone pastes code into a prompt and the code happens to contain a secret — an API key that should be in an environment variable but ended up hardcoded, a connection string with credentials embedded, a config file with an account identifier. The code looks fine in the local IDE context where the developer knows what they're looking at. It looks like a data breach in a model provider's request log.
The prevention is automatic secret scanning at the prompt level, run before the prompt reaches the provider abstraction layer:
SENSITIVE_PATTERNS = [
r'[A-Za-z0-9_-]{32,}', # long random strings (API keys)
r'postgres://[^@]+@[^\s]+', # database connection strings
r'[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}', # email addresses
r'\b\d{3}-\d{2}-\d{4}\b', # SSNs
r'\b(?:4[0-9]{12}(?:[0-9]{3})?|5[1-5][0-9]{14})\b', # credit card patterns
]
def scan_for_secrets(text: str) -> list[str]:
findings = []
for pattern in SENSITIVE_PATTERNS:
matches = re.findall(pattern, text)
findings.extend(matches)
return findings
def validate_prompt(prompt: str) -> None:
findings = scan_for_secrets(prompt)
if findings:
raise PromptSecretError(
f"Potential secrets detected in prompt: {len(findings)} matches. "
"Review and remove before sending to model provider."
)
This scan runs on every prompt that goes through the orchestration layer. False positives are possible — a long random string might be a UUID that's not actually a secret. The scan raises an exception and requires human review of the flagged content. That friction is intentional.
Rule 2: Scope the Context
Every token in a prompt has a cost — monetary for cloud models, latency for local models, and cognitive for the model's attention. Pasting entire files into a prompt when only a function is relevant is wasteful and counterproductive. The model's attention is diluted by the irrelevant content.
The discipline of scoping context — sending only what's relevant to the current task — also has a secondary benefit: it forces clarity about what is actually relevant. If you can't identify the relevant portion of a file, you probably haven't thought clearly enough about what you're asking the model to do.
The knowledge retrieval system is part of the answer here. Retrieved context is already scoped — the retrieval step returns the five or ten most relevant entries, not the entire knowledge base. The limit on retrieved context length is enforced at the retrieval layer.
Rule 3: Explicit Instructions Over Implicit Assumptions
A prompt that relies on the model inferring what you want is a prompt that will fail in unpredictable ways. The model will infer something. Whether it infers what you intended depends on how similar your intent is to the intent of the prompts in the model's training data.
Explicit instructions don't guarantee correct output, but they define what correct output looks like in a way that the output verification step can check against. "Return a JSON object with keys 'findings' (list of strings) and 'severity' (one of: low, medium, high)" is verifiable. "Review this code and tell me what's wrong" is not.
Rule 4: Log Everything
Every prompt, every response, every model call in the orchestration layer gets logged. Not just the final output — the intermediate steps, the retrieved context, the routing decision, the model and provider selected, the token counts, and the verification outcome.
This logging is not for debugging during development. It's for auditing when something goes wrong in production. "The AI generated incorrect code" is not useful after the fact. "The AI generated incorrect code because the retrieved context included a stale entry from three months ago that described a different version of the API" is useful — it tells you what to fix.
The log also provides the data to improve the system over time. Patterns in failures point at specific failure modes. Patterns in successes point at what's working. Without structured logs, you're flying blind on where to invest improvement effort.
The Cumulative Effect
None of these rules is individually surprising. Applied consistently, together, they produce a workflow that's meaningfully more trustworthy than one that treats prompts as ad hoc text. The secret scanning catches the most dangerous failure mode. The context scoping improves output quality. The explicit instructions make output verifiable. The logging makes the system auditable.
Prompt hygiene is infrastructure, not polish. It belongs in the design phase, not the cleanup phase. As always, I'm here to help if you want to compare notes on specific hygiene rules or enforcement approaches.