Political Risk and Model Availability


There's a category of risk in AI tooling that doesn't get discussed much in technical blogs because it feels abstract until it isn't: the risk that a model you've built on becomes unavailable for reasons that have nothing to do with the model's technical quality or the provider's business health.
I started thinking about this seriously after a specific event: a major AI model was made unavailable in several jurisdictions due to regulatory intervention. The model itself was fine. The provider was fine. But if you were in one of those jurisdictions and had built a workflow dependency on that model, you had a problem — and you had no advance notice and no transition period.
The Geopolitical Dimension of Model Availability
Most enterprise software has some form of regulatory risk — data residency requirements, export controls, sector-specific restrictions. AI models have all of those, plus an additional layer: the models themselves are increasingly subject to government scrutiny in ways that can restrict access suddenly and without the kind of transition periods that enterprise software customers expect.
The risk runs in multiple directions. A model developed by a US company may become restricted in certain international markets due to export control changes. A model developed by a company in a different jurisdiction may become restricted in the US or EU due to security concerns or data handling requirements. A model that's currently permitted may become subject to new restrictions as AI-specific regulation develops in major markets.
None of these risks are hypothetical. All of them have precedents in analogous technology categories. The question is not whether model availability will be affected by regulatory action, but when and how often.
The Provider Diversity Response
The engineering response is the same as the response to any availability risk: don't build a single-point dependency. Provider diversity in the model layer means that a regulatory restriction affecting one provider's models doesn't take down your entire workflow — it just requires routing those tasks to an alternative provider until the situation resolves.
The interesting implication for provider selection: diversity should include providers operating in different regulatory environments. A stack that uses only US-based providers is less resilient to US regulatory action than a stack that also includes providers based in the EU or other jurisdictions with different regulatory regimes. This is the same logic that drives geographic redundancy in traditional infrastructure — you're building in resilience to a class of risk that's correlated within a single regulatory environment.
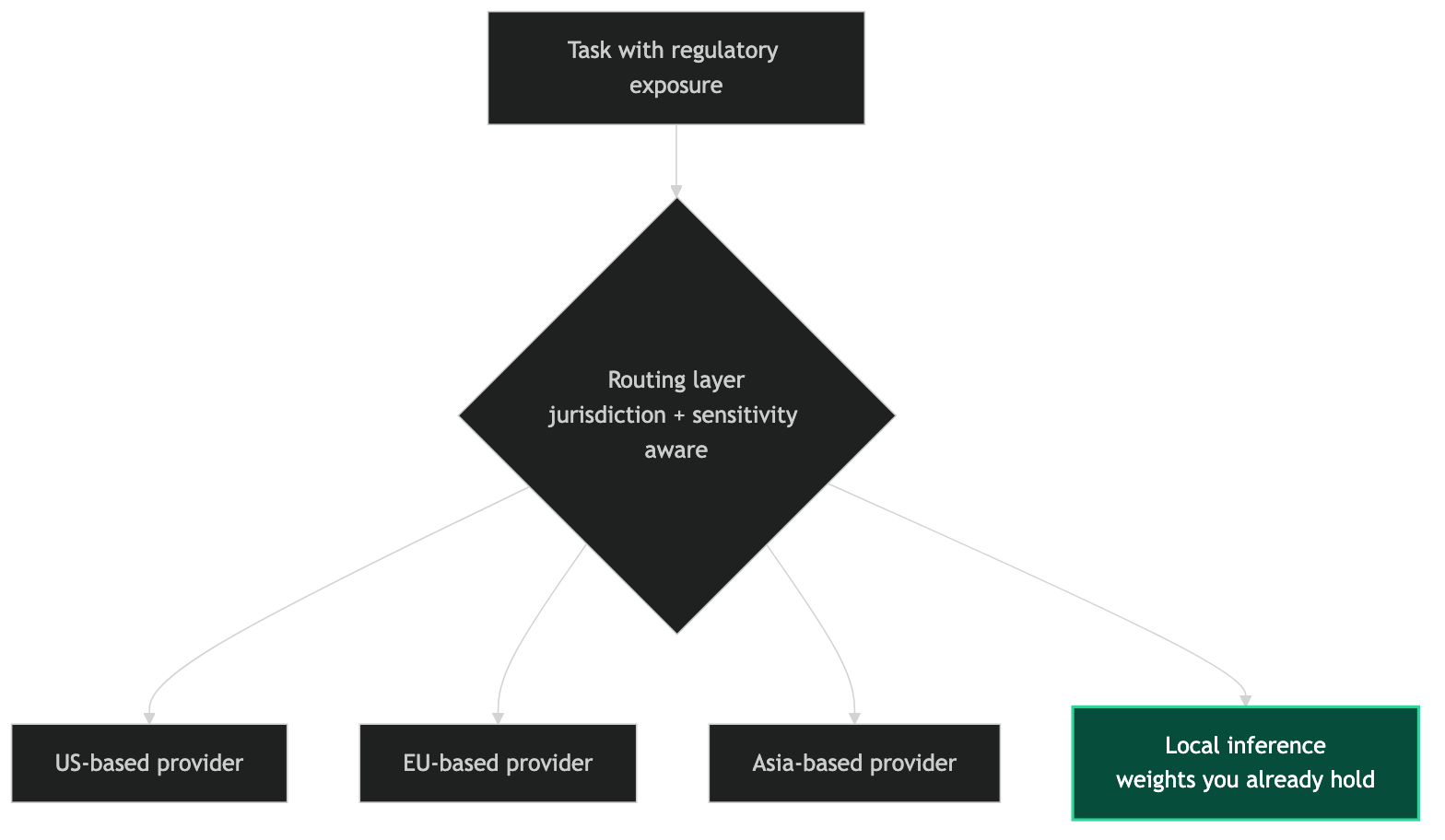
The EU AI Act has created a different compliance environment than US AI policy. Models compliant with EU requirements may not be the same models that optimize for US market preferences. Providers based in Asia operate under yet another regulatory environment. Having options across these environments provides meaningful resilience that a single-provider stack cannot.
The Local Model Argument, Again
Local models are the most resilient option along the regulatory risk dimension. A model running on hardware I own, in a jurisdiction I operate in, with weights I have already downloaded, is not affected by a provider's regulatory status in any other jurisdiction. It's also not affected by provider business continuity, pricing changes, or terms of service updates.
The capability tradeoff is real — local models at accessible hardware costs don't match the top-end cloud models on complex reasoning tasks. But for the structured tasks that constitute most routine workflow steps, local models are adequate. And "adequate for most tasks, with cloud supplement for tasks that require higher capability" is a reasonable architecture when that cloud supplement is also diversified across providers.
The Practical Implementation
My current provider roster spans multiple jurisdictions and includes local inference. The routing logic considers regulatory exposure for high-sensitivity tasks: tasks involving data that has jurisdiction-specific handling requirements get routed to providers operating under the appropriate regulatory framework, or to local inference when the jurisdiction question is most important.
This is not a fully solved problem. Regulatory environments change faster than routing logic gets updated. The goal is not perfect regulatory compliance automation — it's to not have a single provider failure mode that takes down the whole workflow. On that goal, the current setup is adequate. As always, I'm here to help if you want to compare notes on how you've thought about provider diversity from a risk management perspective.