Open-Weight Models in Production: The Deployment Reality Check


Llama 4, DeepSeek V3.2, Mistral Large 3 — the open-weight model landscape at the end of 2025 is genuinely competitive with closed frontier models for a wide range of tasks. That's the good news. The deployment reality has some friction that's worth understanding before you commit to an on-premises or self-hosted inference strategy.
The Hardware Requirement Is Not Trivial
Running Llama 4 Maverick (400B total parameters, 17B active per token in MoE) in a configuration that produces acceptable throughput for production workloads requires meaningful GPU infrastructure. The MoE architecture means active compute per token is much lower than the parameter count suggests, but you still need the full model loaded across multiple GPUs for the router to function correctly. Verify your hardware budget before you commit to self-hosted Maverick.
Scout (109B total, 17B active) is more accessible, and for most pipeline tasks the quality gap between Scout and Maverick is smaller than the infrastructure cost gap.
Databricks Foundation Model APIs as the Middle Ground
For teams on Databricks, the Foundation Model APIs are the pragmatic on-ramp: you get open-weight model inference without managing the GPU infrastructure yourself. The models run in Databricks' infrastructure, your data doesn't leave the platform, and you pay per token. It's not as cheap as true self-hosted, but the operational overhead is near zero compared to managing your own GPU cluster.
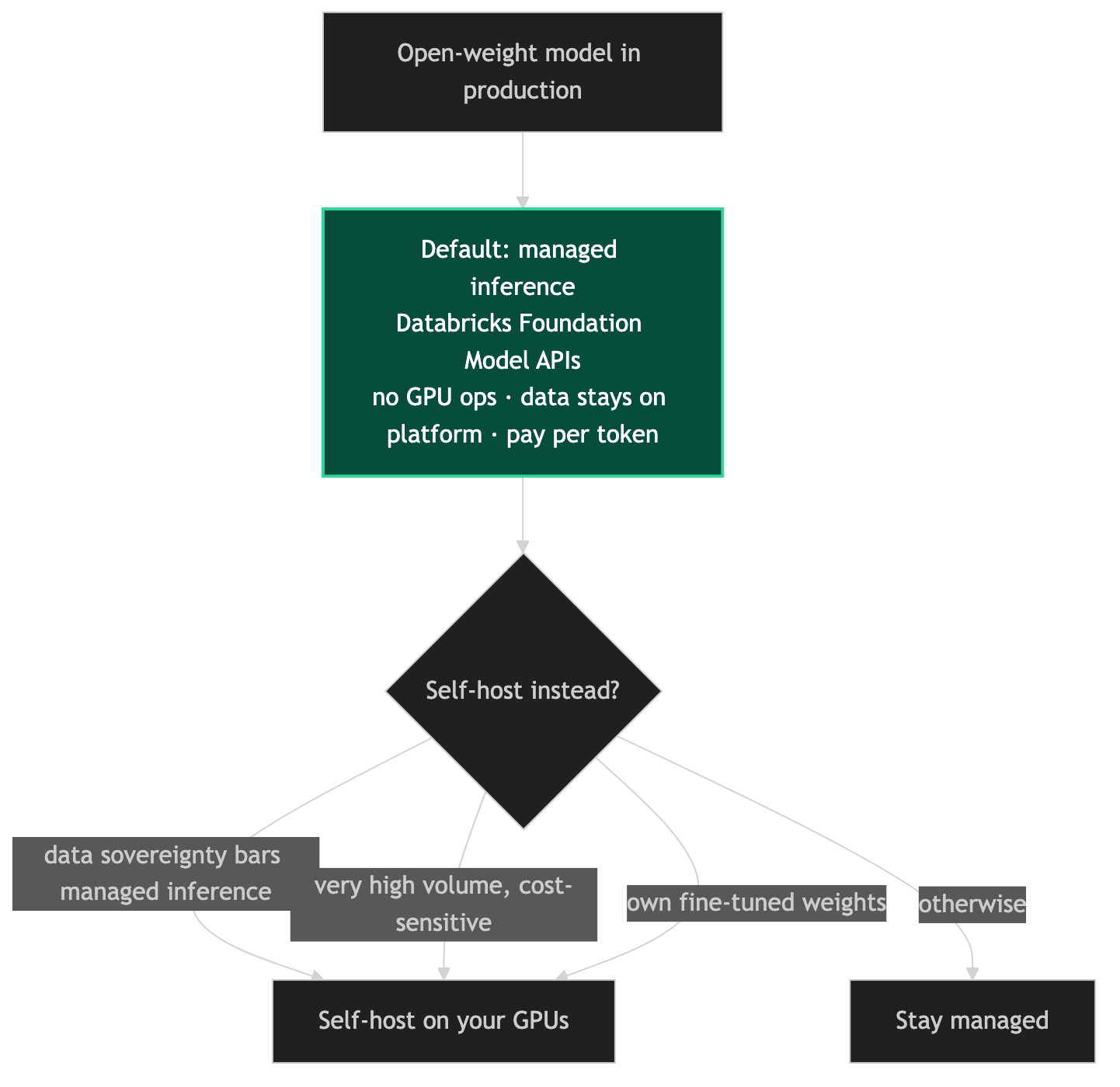
When Self-Hosted Makes Sense
Data sovereignty requirements that prohibit even Databricks-managed inference. Very high-volume, cost-sensitive workloads where the per-token savings of owned hardware cover the ops cost. Fine-tuned models where you own the weights and can't load them on a shared platform. For most teams, managed inference on Databricks Foundation Models is the right call until volume justifies the infrastructure investment. I'm here to help work through the economics for your specific workload.