Model Pricing Shockwaves and Why Lock-In Is Now a Liability


The economics of AI model access shifted faster in early 2026 than anyone I spoke to had anticipated. Price per token changes, tier restructuring, capability gating behind higher subscription tiers, and model deprecations on compressed timelines — these arrived in close succession and in ways that exposed an uncomfortable dependency for anyone who had built deeply on a single provider.
This is not a complaint post. It's a post about what happened when provider lock-in met an unstable pricing environment, and what the right engineering response looks like.
What Changed and Why It Mattered
The specific price changes were less important than their pattern. Multiple providers simultaneously repriced their most-used models — not in a direction that made costs more predictable, but in a direction that required actively re-evaluating which provider was the right choice for which task. The cost calculus that was correct three months ago was no longer correct, and the recalculation was not trivial.
For anyone who had hardcoded provider choices — specific model strings in configuration, pricing assumptions baked into billing estimates, integration code that assumed a specific API shape — the repricing events were operational work. Update the configurations, re-evaluate the task routing, re-run the cost projections, update any billing-aware logic.
For anyone running a provider-agnostic architecture with a routing layer, the repricing events were configuration changes. The routing logic already accepted "which provider is the right choice for this task type at the current price point" as a runtime decision. Updating that decision meant changing a few lines of configuration, not refactoring integration code.
That difference — operational work vs. configuration change — was the clearest validation of the provider-agnostic design I had seen since building it.
The Lock-In Taxonomy
Not all lock-in is the same. Understanding which types you're exposed to helps prioritize where to invest in abstraction.
API format lock-in: your code assumes a specific API contract — specific request shapes, specific response formats, specific authentication patterns. The hardest to fix retrospectively because it's typically spread through the codebase. The provider abstraction layer I built addresses this.
Model capability lock-in: your workflow assumes specific capabilities available only from one provider — a specific context window size, a specific tool-use API, a specific multimodal capability. Addressable by designing workflows that can adapt to different capability levels, with the best-capability provider as the preferred path and a capable-enough alternative as the fallback.
Pricing lock-in: your cost model assumes a specific price point and you've made decisions (task granularity, batching strategy, tier selection) based on that price point. The least obvious form of lock-in until prices change, at which point it becomes the most immediately painful.
Data gravity lock-in: your data has accumulated in a provider's proprietary format or storage system in a way that makes migration expensive. Not directly applicable to model API usage, but worth noting for anyone who also uses provider-specific storage or fine-tuning services.
The Routing Layer Update
When the pricing environment changed, updating the routing layer was the immediate task. The cost-aware routing logic had been a placeholder in earlier versions — it route based on task type and data sensitivity, but it didn't account for current pricing in a dynamic way.
The update added a cost configuration layer:
# provider_costs.yaml — updated when pricing changes
providers:
anthropic:
claude-sonnet-4-6:
input_cost_per_1k_tokens: 0.003
output_cost_per_1k_tokens: 0.015
openai:
gpt-4o:
input_cost_per_1k_tokens: 0.0025
output_cost_per_1k_tokens: 0.010
ollama:
hermes3:8b:
input_cost_per_1k_tokens: 0.0 # local, no token cost
output_cost_per_1k_tokens: 0.0
The routing layer reads this configuration at startup and uses it as one factor in routing decisions. When costs change, updating the YAML file changes the routing behavior. No code changes required.
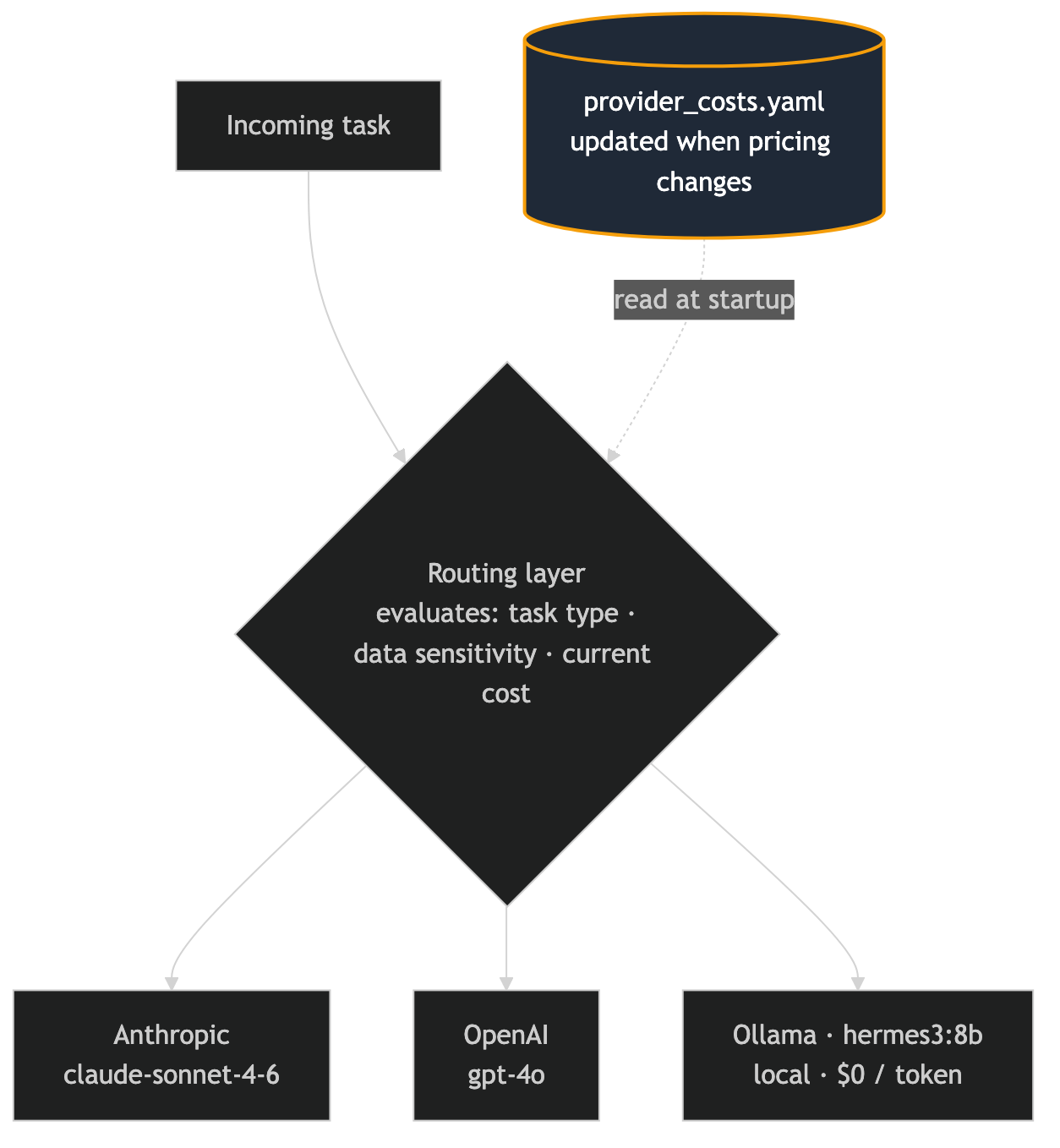
provider_costs.yaml, not a code change.This isn't a perfect solution — the routing logic still requires human judgment about what the right tradeoffs are at the current price points. But it makes the update a configuration task rather than a code task, which is the right level for a decision that needs to be revisited whenever pricing changes.
The Broader Implication
Pricing instability in the model provider market is not a temporary condition. The market is still early, still competitive, and still figuring out what the right price points are. Anyone building production AI workflows should treat pricing changes as a recurring operational event, not a rare exception.
The engineering response is not to lock in the current best price — it's to build a system that can route efficiently at whatever the current prices are. That requires provider agnosticism, cost-aware routing, and the operational discipline to update the cost configuration when prices change.
The organizations that will handle the next pricing disruption best are the ones whose AI infrastructure is already designed to route around it. As always, I'm here to help if you want to dig into the routing architecture details.