Mistral Small 4 and the Economics of Capable Small Models


Mistral dropped Small 4 this month and it continues a pattern that's been building across the open-weight ecosystem: small models are getting much better, much faster than large models are getting marginally better. Small 4 handles code, structured extraction, and classification tasks at a quality level that would have required a significantly larger model a year ago.
For data engineering pipelines, this matters more than the flagship releases.
Why Small Models Matter More for Pipelines
Most LLM calls in a data pipeline don't require frontier intelligence. They require fast, reliable, cheap inference for well-defined tasks: classify this failure type, extract these fields, validate this schema change, generate this SQL template. A well-prompted small model handles all of these at a fraction of the cost of a flagship model.
The practical implication: your default model for pipeline decision points should be the smallest model that achieves acceptable accuracy on your eval suite, not the most capable model available.
Small Model Deployment Options
Mistral Small 4 runs comfortably on consumer hardware — a single A10G handles it without batching constraints. That means you can run it as a sidecar inference service alongside your Databricks cluster, as a container in your k3s infrastructure, or on Databricks Foundation Model APIs without the GPU cost of a larger model. The operational cost of small model inference is low enough that self-hosting becomes viable for teams with modest GPU resources.
The Right Tiering Strategy
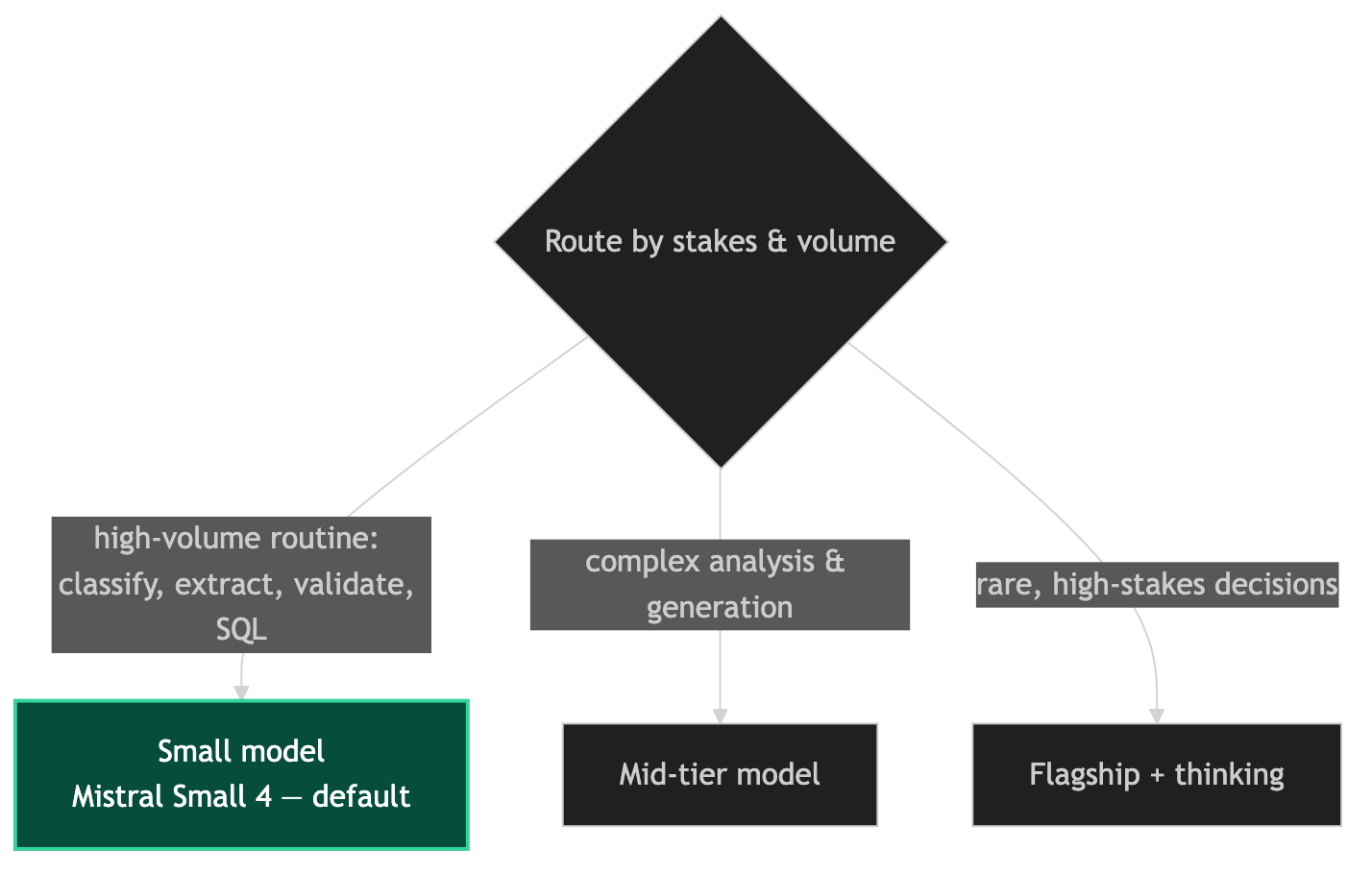
Small model for high-volume routine decisions. Mid-tier for complex analysis and generation. Flagship with thinking enabled for rare, high-stakes decisions that justify the cost. The tiering should be explicit in your routing configuration, not implicit in "whatever model the default is." I'm here to help design the right tier structure for your pipeline workload.