Llama 4 Behemoth and What Trillion-Scale Parameters Actually Buy You


Meta's Llama 4 Behemoth — 2 trillion total parameters, 288 billion active per token — is the largest open-weight model ever previewed. The numbers are designed to impress, and the benchmark results on STEM reasoning and mathematics are genuinely strong. But "biggest model wins" is a lazy frame, and the question worth asking is more precise: what does parameter scale at this level actually give you that a smaller model with more context doesn't?
The answer is more specific than most coverage acknowledges, and it's not what you probably assume.
What the Scaling Laws Actually Say
The empirical data on parameter scaling has been accumulating for years and the picture is clear: different capabilities plateau at very different scales. Code generation performance flattens out around 34 billion parameters. Reasoning on benchmark tasks like GSM8K plateaus around 70 billion. Language understanding hits diminishing returns even earlier, around 13 billion. Beyond those thresholds, you're paying more compute and memory for smaller and smaller marginal gains on those specific tasks.
The Chinchilla result — a 70B model trained on 1.4 trillion tokens outperforming 280B Gopher on nearly every benchmark — is the cleanest demonstration that parameter count isn't the primary lever. Training data quality and volume move the needle more reliably than adding parameters beyond the point of diminishing returns.
So what does scale buy once you're past the task-specific plateaus?
The Long Tail Is the Real Answer
World knowledge follows a power-law distribution. A small number of facts and entities appear constantly in training data; the vast majority appear rarely. Rare medical conditions, regional legal specifics, obscure programming language internals, niche scientific subfields, historical events outside the Western canon — these get seen once or twice during training and need parameter capacity to stick.
A 30B model simply can't memorize enough of the long tail. It will hallucinate confidently on rare domain questions not because it's bad at reasoning, but because the relevant facts were never reinforced enough to be retrievable. A trillion-parameter model, trained on the same corpus, retains more of that low-frequency knowledge — not because it reasons better, but because it has more room to store what it saw.
This is the honest core of what Behemoth's scale buys: breadth of coverage, not depth on any specific task.
Cross-Domain Synthesis on Rare Associations
The other genuine advantage of scale is synthesizing knowledge across domain boundaries that rarely appear together in training data. Connecting distributed systems theory to immunological network topology, or reasoning about the intersection of Byzantine fault tolerance and epidemiology, requires the model to have absorbed rare co-occurrences across disparate fields. Those joint distributions are sparse in any training corpus, and smaller models don't see them often enough to build reliable associations.
This shows up most clearly in STEM tasks that require multi-domain reasoning — which is exactly why Behemoth's benchmark wins cluster there. It's not that larger models reason more deeply within a domain. It's that they've absorbed more of the unusual cross-domain associations that hard STEM problems require.
What Scale Does Not Buy: The Code Generation Case
Here's where the conventional narrative breaks down. Complex code generation — specifically the repository-level kind, where you're generating a multi-file transformation that handles edge cases across a large, complex schema — is not primarily a parameter problem. It's a context problem.
The benchmark evidence is direct. Research comparing models across parameter counts on coding tasks shows a 165M parameter model with an 8K context window matching a 20B model with a 2K context window on the APPS benchmark. At the repository level, what matters is fitting the relevant codebase, schema definitions, and upstream context into the model's working window — not how many parameters the model has. Llama 4 Scout's 10-million-token context window is a more powerful tool for this task than Behemoth's 2 trillion parameters.
There's a compounding factor here that's easy to miss: larger models tend to generate more verbose output. On long-context tasks, verbosity fills the window faster and degrades performance. A well-prompted mid-sized model with a large context often outperforms a frontier model with a cluttered context on this dimension.
If your task is "write a PySpark transformation that correctly handles schema evolution and null propagation across a 40-table medallion architecture," you want Scout with the schema and upstream pipeline context in the window. You don't need Behemoth.
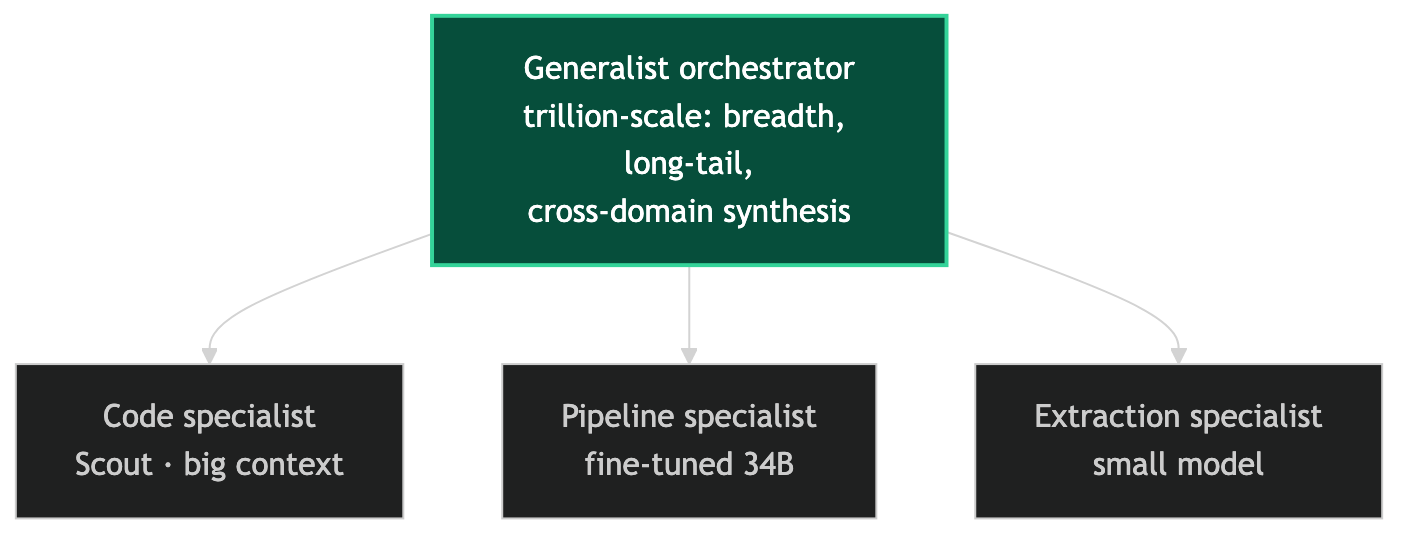
The Orchestrator Frame
The most accurate mental model for what a trillion-parameter model is good for is a generalist orchestrator that needs to cover an enormous surface area. It knows a lot of things about a lot of domains. It can follow unusual instruction formats it wasn't specifically fine-tuned for. It can zero-shot generalize to task types that specialist models don't handle well. It synthesizes across disciplines in ways that require broad training coverage.
That's a valuable capability in an architecture where the orchestrator routes to specialist models for execution. The generalist at the top needs breadth. The specialists underneath need depth and speed. Confusing the two — expecting Behemoth to outperform a fine-tuned 34B model on your specific data pipeline task — is a category error.
The Weights Still Haven't Shipped
One more thing worth stating plainly: Behemoth's public weights have not been released as of this writing. Meta previewed it at the Llama 4 launch and cited internal benchmark results. The claims about STEM performance are from Meta's own evaluations on their own benchmarks. Until the weights ship and the community runs independent evals — particularly on tasks outside the specific benchmark suite Meta chose — the real-world performance profile is not fully known.
That matters for how you plan. If you're making infrastructure decisions based on Behemoth, you're betting on a model you can't currently run, evaluated on benchmarks chosen by the organization that trained it. Build the architecture that the weights you actually have access to can support, and make room to plug in Behemoth if and when it ships and earns its slot. As always, I'm here to help think through how that fits in your specific stack.