Agent Reliability After Six Months of Production LangGraph Pipelines


I've been running LangGraph-based agents in production for the better part of a year now. Here's an honest accounting of where the reliability challenges actually show up — not the architectural problems that show up in conference talks, but the operational ones that show up on a Tuesday afternoon when something breaks.
The Prompt Drift Problem
Agent behavior is sensitive to prompt changes in ways that don't always surface in unit tests. A change to the system prompt that improves performance on one class of inputs can silently degrade performance on another. If you're iterating on prompts in production without eval coverage, you're flying blind. The fix is non-negotiable: every prompt version gets a version number, every change gets run through your eval suite before deployment.
The Long-Tail Failure Modes
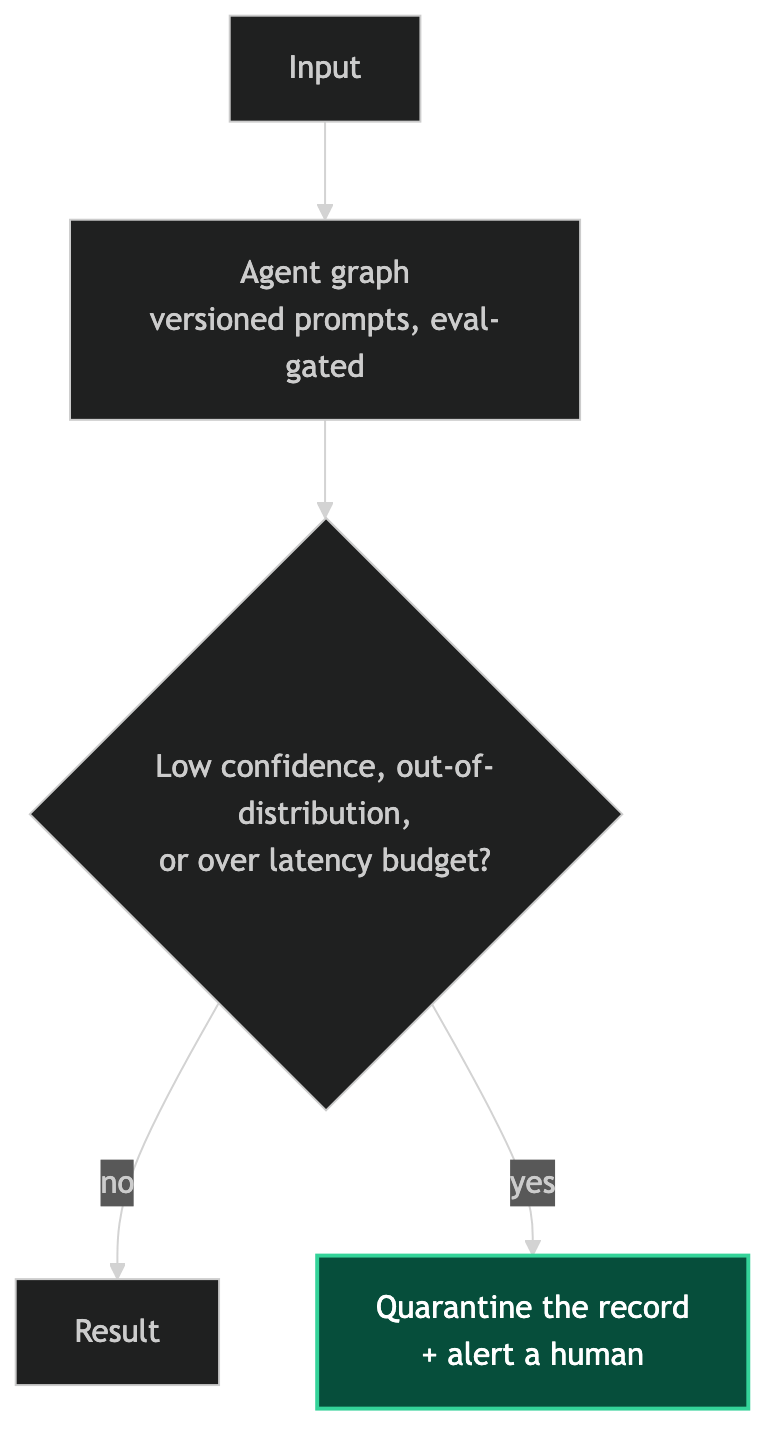
The failure modes that show up most often in production aren't the ones you designed for — they're the inputs that fall outside the distribution you tested against. An extraction agent trained on clean text will fail quietly on text that includes special characters, unicode issues, or unexpected formatting. The fix is adding those cases to your eval suite as you discover them, and maintaining a quarantine path for inputs the agent expresses low confidence on.
Latency Budgets and Their Violations
Multi-step agent workflows accumulate latency. A five-node graph where each node calls an LLM with a 2-second median latency has a 10-second median end-to-end time — and a much longer 99th percentile when one call hits a cold model or a network hiccup. For workflows that block downstream processes, set explicit timeouts at the graph level and design the timeout path to be safe (quarantine the record, alert a human) rather than destructive (assume success). I'm here to help design the reliability layer for your specific pipeline.