Adding Ollama: The Case for Local Inference


Local inference has been on the periphery of the AI tooling conversation for a while — interesting to enthusiasts, impractical for most use cases, always "getting better" but never quite ready for production work. That narrative has shifted. Running capable models locally on commodity hardware is now a reasonable production option, not just a hobbyist experiment. Here's what adding Ollama to the provider stack actually looks like in practice.
Why Local Inference Now
Three things changed around the same time to make local inference worth serious consideration: hardware that can run interesting models at reasonable speeds became available at reasonable prices; model quantization improved to the point where 8B and 13B parameter models can fit in the VRAM of a mid-range consumer GPU without quality degradation that matters for the tasks I care about; and the Ollama project made running those models operationally simple enough that the setup overhead stopped being a barrier.
The specific hardware I'm running: a machine with 128GB RAM and two NVIDIA GPUs with 16GB VRAM each. Not a server rack — a workstation. The cost was significant but not enterprise-significant. Models that fit in that VRAM run inference fast enough for interactive use. Models that don't fit run on CPU, which is slower but still usable for batch tasks where latency is not the primary constraint.
The Ollama Setup
Ollama's operational model is intentionally simple. You run a server process, you pull model weights, you query the API. The API follows the OpenAI format closely enough that adapters written for OpenAI work with minimal modification:
class OllamaProvider(ModelProvider):
def __init__(self, base_url: str = "http://localhost:11434"):
self.base_url = base_url
def complete(
self,
messages: list[dict],
model: str,
max_tokens: int = 4096,
temperature: float = 0.0,
**kwargs,
) -> ModelResponse:
response = requests.post(
f"{self.base_url}/api/chat",
json={
"model": model,
"messages": messages,
"stream": False,
"options": {
"temperature": temperature,
"num_predict": max_tokens,
},
},
)
data = response.json()
return ModelResponse(
content=data["message"]["content"],
model=model,
provider="ollama",
input_tokens=data.get("prompt_eval_count", 0),
output_tokens=data.get("eval_count", 0),
finish_reason="stop",
)
The adapter is straightforward. The operational benefit — data that goes into this provider call never leaves my machine — is not.
What Local Models Actually Handle Well
After several months of routing tasks through local models, the capability profile is clear. Local models handle structured tasks well: code generation from a specification, JSON output from a schema definition, classification against a defined set of categories, summarization of technical content. They handle open-ended reasoning less well: tasks that require multi-step logical deduction on novel problems, or tasks where the output quality depends heavily on depth of training data.
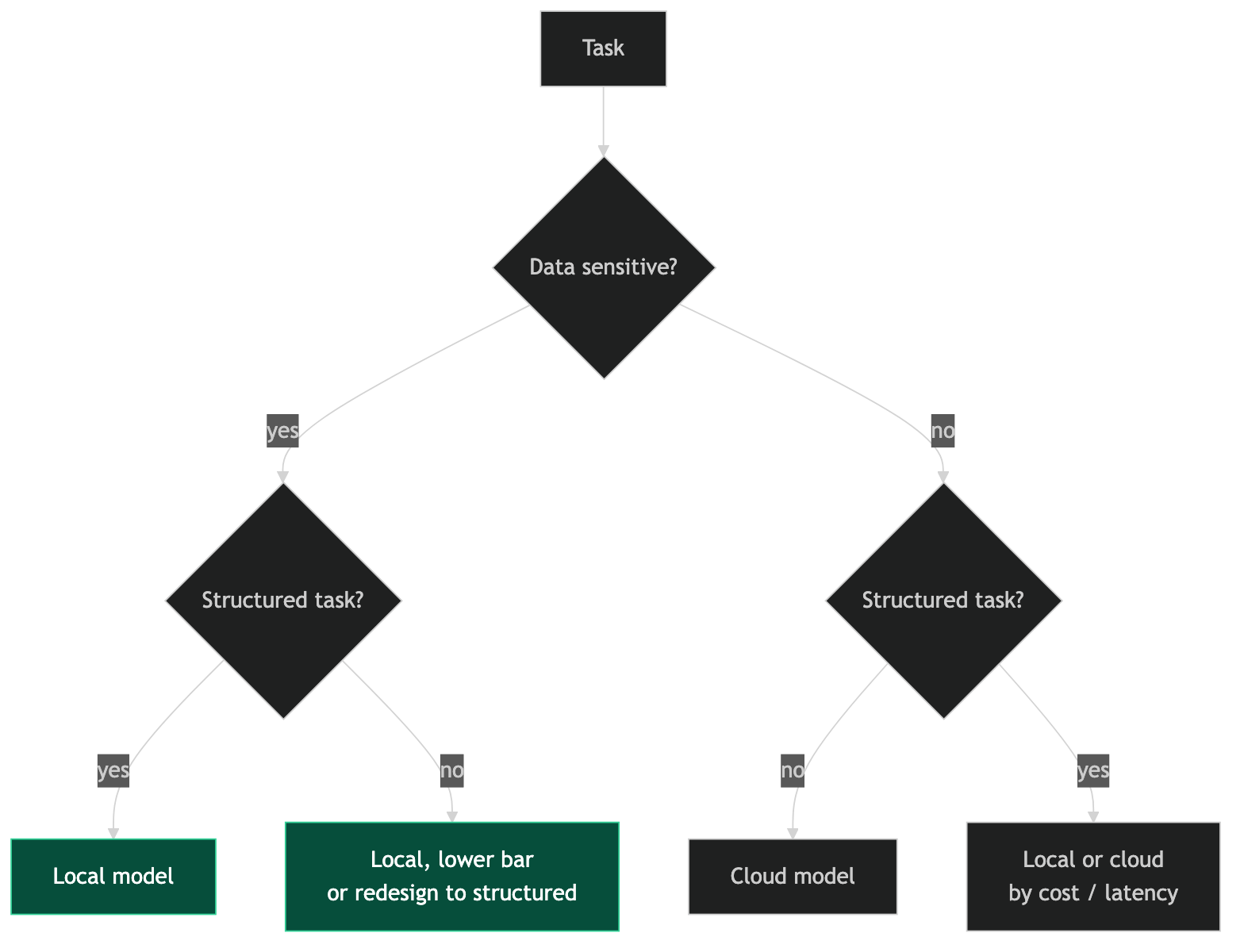
The routing decision for local vs. cloud follows from this profile:
- High data sensitivity + structured task → local model
- High data sensitivity + complex reasoning → local model with lower quality expectations, or task redesign to make it structured
- Low data sensitivity + complex reasoning → cloud model
- Low data sensitivity + structured task → local or cloud based on cost and latency requirements
Most of the tasks in my day-to-day orchestration workflow are structured tasks. Code generation. Review against a defined checklist. Output formatting. These tasks run well on local models, which means most of the routine workflow can run locally. The cloud providers handle the smaller fraction of tasks that require the deeper reasoning quality they deliver.
The Cost Profile
Local inference has a different cost structure than cloud inference. The hardware cost is a capital expense, paid once. The electricity cost is ongoing but small — running inference on a GPU for several hours a day is measurable but not significant at residential rates. The token cost is zero.
For high-volume inference, local becomes cheaper than cloud at some threshold that depends on hardware cost and cloud pricing. For the volumes I'm running, the hardware has already paid for itself in token costs avoided, and that calculation improves as the hardware ages and cloud prices change.
The less quantifiable benefit: inference that doesn't depend on cloud provider availability. When a cloud provider has an outage, the local models keep running. When cloud pricing changes, the local models' cost profile is unchanged. When a model is deprecated by its provider, the local model weights I pulled are still available until I choose to remove them.
That operational independence is worth something. It's harder to put a number on than token cost savings, but it's the thing I notice most in practice. As always, I'm here to help if you want to compare notes on the local inference setup.